

Quels sont les différents types de données générées automatiquement ? Quelles est le rapport entre l’IoT et le Big Data ? Et surtout, que peut-on attendre de la science de l’analyse des données pour l’Internet des Objets ? L’ambition de cet article est de tenter une réponse simple (et assez scolaire, je l’avoue) à ces questions compliquées et de développer un point de vue basé sur des publications d’acteurs de premier plan.
Bonne lecture 🙂 !
La data science commence dans notre environnement quotidien
Quel est le point commun entre passer ma carte de fidélité à la caisse du supermarché, utiliser mon application de géolocalisation favorite ou amener mon véhicule à un contrôle technique ? A priori aucun, en première approche ces situations sont très différentes. Et pourtant, le plus petit dénominateur commun de ces scènes de la vie courante c’est la production automatique de données ! Omniprésentes et invisibles, elles quantifient méticuleusement le monde réel sans que l’on y fasse particulièrement attention.
D’où viennent ces données automatiques ?
Cette remontée de data a plusieurs facteurs de déclenchement, que l’on peut classer en deux grandes catégories : celles qui ont une causalité humaine directe et celles qui sont produites par des machines sans espèce d’intervention.
Pour les causes humaines, on peut distinguer plusieurs sources de déclenchement : les actions physiques (passage d’un portique, le déclenchement d’une chasse d’eau etc.), les interactions avec un terminal numérique (application, borne numérique, etc.) et les enregistrements d’informations dans un fichier (formulaire, communication de données personnelles etc.). Discrétisés puis consignés, nous alimentons sans le savoir de gigantesques entrepôts de données par nos faits et gestes quotidiens.
Contrairement à un tweet ou à une photo, une donnée générée automatiquement n’est pas le fruit de notre volonté immédiate
L’autre source de production de data provient des machines. Bien que restrictif, le concept de relève à distance (télérelève) est capable de générer des données de manière régulière (mode temporisé) ou évènementielle (mode déclenché). Il s’agit d’une pratique courante pour remonter un grand nombre d’informations avec une tendance qui va s’accélérer comme on va le voir.
Bref point historique sur la télémétrie
La collecte d’informations issues de capteurs est utilisée dans l’industrie depuis la fin des années 1980, principalement à titre de maintenance préventive. Appelée Machine-to-Machine (M2M) cette télérelève est aujourd’hui supplantée par un autre concept dont on entend régulièrement parler : l’Internet des Objets (IoT). Comme son nom l’indique, cette manière de transmettre de l’information fonctionne à des échelles plus globales (Internet) et de préférence avec des objets-capteurs et non plus des machines. Ils ont ceci de différent que sans connectivité, l’objet ou le capteur perd toute utilité. Au contraire, la connectivité dans une machine n’est pas essentielle : la retirer n’empêche en principe pas son bon fonctionnement. Pour parler de manière générale de tous ces types de terminaux, on utilise parfois le terme d’appareils connectés (devices).
Cependant, la différence IoT – M2M ne se limite pas seulement à la nature de l’appareil en bout de ligne et la valeur ajoutée de la connectivité. Elle est également technologique puisque les moyens de transmission, les réseaux utilisés, l’autonomie des appareils ou l’intelligence embarquée sont en principe différents. Mais elle est aussi et surtout conceptuelle : l’Internet des Objets impacte des secteurs beaucoup plus variés avec des cas d’usages multiples. Contrairement au M2M, l’exploitation des données issues de l’IoT est complexe et sert de socle à de la prise de décision. Ces données sont en général représentées avec des méthodes graphiques (data-visualisation). Enfin, le volume de données généré par l’IoT est en principe plus grand de plusieurs ordres de grandeurs par rapport au M2M.
Humains ou machines, M2M ou IoT : la certitude est que le monde autour de nous est en permanence retranscrit en jeux de données qui sont de plus en plus volumineux.
Les appareils connectés vont devenir une source prépondérante dans la production de données
Souvenons-nous du temps analogique ! Durant des millénaires la production matérielle, intellectuelle et artistique assimilable à des données était exclusivement le fruit de l’Homme. Devenue digitale, la production engendrée par l’humain (documents, tweets, dessins industriels, photographies…) est vouée à devenir minoritaire face aux volumes générés automatiquement par les appareils connectés et les algorithmes. Ce phénomène est visible pour l’IoT dans l’illustration ci-dessous qui prend une part de plus en plus importante par rapport à l’ensemble des données produites et stockées à l’échelle de la planète. On appelle ce volume global l’Univers Numérique (ou DU pour Digital Universe) qui est lui-même en croissance forte.
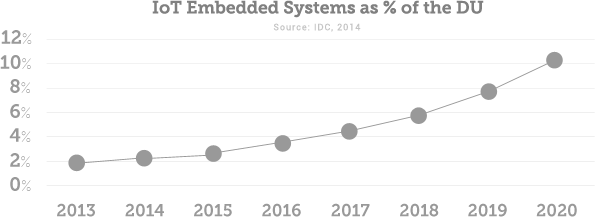
Les systèmes embarqués de l’Internet des Objets génèrent des quantités de données en croissance exponentielle. Ils deviendront prochainement le premier volume de données.
Source : EMC/IDC, « Digital Universe of Opportunities », 2014
Des quantités de plus en plus importantes
Après 2010, le phénomène d’accélération dans la production de data a bénéficié d’une large couverture médiatique et d’une prise de conscience collective.
Cette année-là, Eric Schmidt, le patron de Google, estimait déjà que « tous les deux jours, nous produisons autant d’informations que nous en avons générées depuis l’aube de la civilisation jusqu’en 2003 ».
En 2017, on estime que la taille de l’Univers Numérique croit de 40% par an (1) ce qui pourrait représenter 44 000 milliards de gigaoctets en 2020, soit 10 fois plus qu’en 2013 (2). N’essayez pas de vous représenter ce volume, cela dépasse l’entendement.
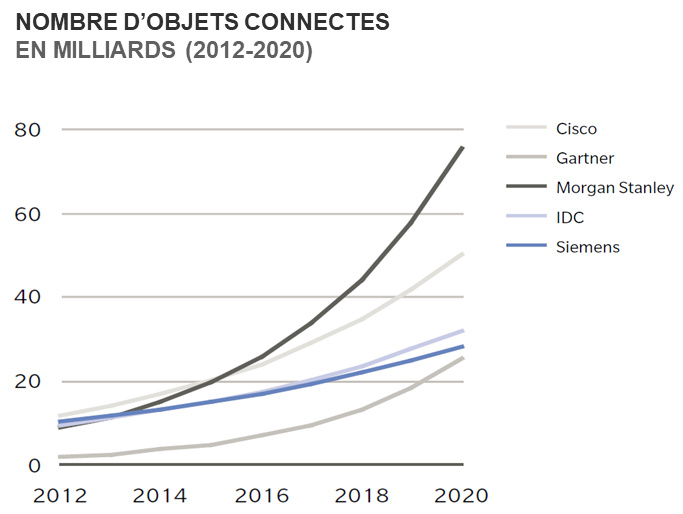
Prévision du nombre d’objets connectés dans le monde : leur augmentation a un impact direct sur le volume d’informations croissant généré par l’IoT. Cette croissance est plus rapide que celle de l’Univers Numérique ce qui aboutit à un ratio Vol(IoT) de plus en plus important.
Source : Oliver Wyman, 2016
Avec 10% de l’Univers Numérique en 2020 et en croissance exponentielle, on estime que les données brutes produites par l’ensemble des appareils connectés deviendront rapidement le volume de données le plus important. Il dépassera la production de type algorithmique qui se base sur l’analyse des jeux de données existants (modélisation, traitement statistique…) ou sur une production ex nihilo (cryptographie, simulation, apprentissage profond…) ainsi que la production humaine directe.
Boosté par la généralisation de l’IoT, le volume de données va exploser à l’échelle mondiale. Si le stockage de l’information semble aujourd’hui relativement maîtrisé, la question fondamentale tourne autour de l’exploitation de ces gigantesques entrepôts de données (datawarehouse).
Des données déjà nombreuses, mais pas forcément utilisables
Un rapport publié en 2016 rend compte d’un phénomène de fond : 85% des données en entreprise seraient aujourd’hui non pertinentes (3).
Cela interroge sur la qualité et l’exploitabilité des données collectées d’une part. D’autre part, il faut mettre ce chiffre en perspectives avec les limites algorithmiques de l’exploitation des jeux de données : une problématique courante chez les géants du web, dans les secteurs du Renseignement et de la Défense, ou dans la recherche scientifique lorsque l’on parle d’association de collections de données extrêmement volumineuses (4). Cette limite est un sujet primordial et est actuellement l’objet d’intenses recherches.
L’évolution vers un Internet des Objets intelligent dépend des avancées de la science des données
La taille de l’Univers Numérique croit, les appareils connectés génèrent en proportion toujours plus de données (et pas toujours utiles) que l’on n’arrivera bientôt plus à exploiter. Se dirige-t-on vers un scénario catastrophe ? J’ai tendance à croire que non : avec l’effet combiné de la recherche sur le sujet, de l’augmentation des puissances de calcul et de prises de conscience simples (« quantité ne signifie pas qualité »), il semble que l’on puisse faire des progrès significatifs. Dans cette partie, je vous propose un tour d’horizon des prochaines étapes clés menant vers des réseaux d’objets connectés plus intelligents.

© blog.alexandre-gambuto.com, librement inspiré d’une intervention de Alcatel-Lucent
– Phase I : enjeux déjà maîtrisés
Collecte de données : il s’agit de la transmission de l’information et de son stockage. La transmission se fait aujourd’hui à bas coût avec un large spectre de technologies et ne semble pas constituer un frein majeur pour l’IoT. Côté stockage, la formalisation des bases relationnelles dans les années 1970 pose les fondements du stockage structuré qui est encore utilisé de nos jours. À la fin des années 2000 le modèle relationnel est remis en cause pour certaines problématiques de performance et dans un souci de scalabilité. Apparaît le stockage non structuré avec des solutions dites noSQL, qui connaissent un grand succès et représentent aujourd’hui la majorité des données stockées.
Monitoring, reporting : il s’agit du traitement de la donnée. Pour du temps réel on parlera plutôt de monitoring (indicateur d’état dynamique) et pour une analyse consolidée sur un jeu « à froid » on parlera plutôt de reporting.
Exemple : sur un tableau de bord d’une voiture l’afficheur de vitesse peut être considéré comme du monitoring alors que l’analyse des rythmes de production du mois sur un TCD d’Excel est du reporting.
Contrôle à distance : il s’agit de l’envoi d’informations ou d’ordres vers des appareils connectés capables de la recevoir dans un premier temps, de l’interpréter et de réagir. Cela concerne les objets ayant un minimum d’intelligence embarquée (i.e non limités à un simple capteur unidirectionnel).
Exemple : piloter une cocotte-minute connectée à distance
– Phase II : les enjeux actuels
Modélisation : la modélisation de jeux de données est la capacité à trouver un motif élémentaire redondant et/ou un schéma mathématique qui décrit les tendances d’évolution du système.
Exemple : une fonction périodique, un modèle proie-prédateur
Knowledge-based system : il s’agit de la capacité à cataloguer un grand nombre de modélisations de données dans un contexte particulier, que l’on peut appliquer rapidement à un jeu du même contexte.
Prédictibilité : cette étape vient naturellement comme la suivante, elle décrit la capacité à identifier rapidement le modèle qui convient et pouvoir anticiper les évolutions futures et quantifier l’incertitude.
Le contrôle intelligent : cela revient à optimiser un système de manière automatique et en temps réel, en associant la prédictibilité au contrôle à distance du parc d’objets.
La principale difficulté de la mise en place d’un contrôle intelligent provient de la taille des collections de données. L’essor du Smart (City, Grid, IoT) est majoritairement rapporté à un problème de Big Data.
– Phase III : futurs enjeux
L’enjeu ultime est l’intégration d’une couche d’apprentissage profond dans l’ensemble de la chaine de valeur. L’interopérabilité est un enjeu de taille puisque ce système pourrait devenir global. Il aurait ainsi la capacité à se modéliser lui-même et de s’appliquer automatiquement un contrôle intelligent à des fins d’optimisation.
Si ce lointain rêve devient réalité dans les prochaines décennies, on pourra peut-être se rappeler des mots du célèbre physicien Stephen Hawking, à qui l’on doit des avancées théoriques significatives dans le domaine de la cosmologie :
« Réussir à créer une intelligence artificielle serait le plus grand événement dans l’histoire de l’homme. Mais ce pourrait aussi être le dernier. »
Ou encore :
« L’impact à court terme de l’intelligence artificielle dépend de qui la contrôle. Et, à long terme, de savoir si elle peut être tout simplement contrôlée. »
Nous voilà prévenus !
- Pwc
- EMC/IDC, 2014
- Databerg 2016, Veritas Technologies
- Le Big Data un enjeu économique et scientifique, CNRS